Robust Automatic Bulgarian Speech Recognition with INSAIT’s BgGPT
Summary
If you are a Bulgarian company using Google Meet, you have likely experienced the limitations of default transcription models specifically for Bulgarian speech.
Tags
Published
Authored By
Technical Director
If you are a Bulgarian company using Google Meet, you have likely experienced the limitations of default transcription models specifically for Bulgarian speech. We certainly did. At Cosmos Thrace, this pushed us to look for a more robust Bulgarian speech-to-text solution capable of handling noisy, overlapping, real-time audio streams.
We evaluated multiple transcription models and found that Whisper V3 Turbo offered the best balance between computational cost and transcription accuracy across our benchmarks. Although Whisper was originally released in 2022, it remains highly relevant. Its large-scale weakly supervised training makes it particularly robust to accents, background noise, and varied recording conditions [1]. The active faster-whisper community has further improved performance and usability, making the model fast and practical for production environments.
For our use case, Whisper delivered consistently strong results, however, when reviewing the transcripts more closely, we noticed multiple recurring, easily correctable errors. While minor at first glance, these mistakes became an obstacle during downstream tasks such as named entity recognition and even during simple transcript review. Even the strongest ASR systems tend to produce systematic errors, especially in real-world conversational audio, which we describe in the next section. Recent research shows that large language models can act as effective post-processors for speech transcripts, correcting recognition errors and improving overall readability without modifying the underlying speech model [2,3]. This led us to ask a simple question: could we use a Bulgarian language model to post-process and refine Whisper’s output?
To explore this, we experimented with the latest BgGPT model based on Gemma 3, along with 10 other open-weight and closed proprietary models. We evaluated them on both internal datasets and publicly available data that we manually labeled for benchmarking purposes. Our conclusion was clear. The newest iteration of BgGPT is the best fit for our production needs and likely for many other Bulgarian-language applications as well.
Throughout our explorations of Whisper and other SST models, we observed that errors fall into 5 main categories, ranking them from easy to extremely improbable to fix via LLM:
Grammatical and Spelling Errors
Often, Whisper messes up the grammar or spelling of certain words. The most common mistakes include mixing the subject and non-subject forms of the articles, wrongly substituting often mistaken sounds like “о” vs “у” or “м” vs “н”, and most often names of places, people and institutions. We argue that due to Whisper’s size, the model’s internal reasoning does not go beyond direct transcription and these mistakes are more prominent when the speaker makes phonetic errors, as the model will not correct them by default. Take a look at these examples:
Instead of “Член 22-ри, алинея 6-та”, it recognizes “член 22 -я, линея 6 то”, which is very close, but incorrect.
This is trickier, since “Деплой” is a transliteration of a foreign word. Nevertheless, “деплони” is not an existing word, and should be corrected to “деплойне” or possibly “deploy-не”.
We believe these errors are the easiest to fix without listening to the audio, often also without any context, as the Bulgarian language has rigid rules that are universal. As we already noted, the speakers themselves make a substantial amount of such mistakes, but in our use case, we want to correct these errors as well.
Hallucinated Words
Whisper’s transcription can seldom contain words or whole phrases and sentences that were not actually spoken. This can result in some humorous additions. We are guessing that the training data included subtitles from popular shows, or videos, and perhaps often at the end of such, there are a “Абонирайте се” (Subscribe!) or “Благодаря че изгледахте” (Thank you for watching), “Субтитри от Х” (Subtitles by X).
We caught this behaviour in the following news segment:
This is generally easy to fix, as hallucinated segments are trivially identifiable as they appear out of context or as incoherent speech.
Major Phonetic Errors
More exaggerated transcription mistakes can occur when there are multiple speakers, the speaker talks quickly, with few pauses or even slurs their words.
In this example, the model confused “Стабилно Народно Събрание” with “стабилна народността брания”, which does sound relatively close. Through a bit of contextual reasoning, this error is fixable by a human and LLM alike. However, there are some cases where a significant amount of context is lost and we deem the mistake irrecoverable.
Here, “40-50km” is merged as “450km”. Even such a simple omission is usually catastrophic, since the LLM or even a human reading the transcript cannot reliably know there is a mistake, not to mention guessing the correct interpretation, without audio. Rarely, there are cases where stronger reasoning may conclude that, in this example, 450 may be too much for the context (e.g., walking distance) and argue that the speaker meant 40-50, but it is not robust.
Foreign Тerm Мisrecognition
While delving into the nuances of robust ASR, we wondered about the rules of intermixing foreign words without translation, as it does not even qualify as standard Bulgarian formally. In technologically-related conversations, we often use English terms, which do not have convenient translations. Moreover, mixing in English words has become increasingly common in modern Bulgarian speech. It is difficult for models to recognize this code-switching phenomenon and it presents one of the greatest challenges for this task.
As far as orthography goes, the most accepted method for the incorporation of such words and phrases is to phonologically map them and apply the grammatically appropriate suffixes. For example, “to dockerize” would be transformed into “да докърайзне”. The option “да dockerize-не” is also accepted.
Here, the developer obviously meant “dev” as the branch name, but Whisper transcribed it as “ДЕФ”.
For this example, we have to admit, we were unsure what the person meant, but a strong reasoning model such as Anthropic’s Opus figured it out - it was the website strategy.bg, which it determined only based on the context!
Missed Words
A case that can become impossible to fix is when Whisper simply omits words without a clear pattern. Most often, these are connecting words that carry little context, which is not an issue. Still, to be true to the audio, we are expected to add them. But it is not trivial for the LLM to spawn them.
In this example, a lot of connecting words are lost, but generally, they do not carry major context. Rarely does it happen that crucial words to the meaning are omitted, which renders the correct transcript irrecoverable.
Practical Note: If you notice a lot of missed words, this is most probably a VAD filter setting, not a model problem. One has to create a balance between hallucinated words in sections without speech (no VAD filter) and missed words (strict VAD filter). This should be fine-tuned based on the use-case.
ASR fixing instructions
Our LLM prompt is composed of general rules, anecdotal examples to elicit few-shot learning, the transcript lines (3-5) to be fixed as well as some of the context around it.
Test data sources
In our test dataset, we included a parliamentary recording, a podcast, news recordings, and internal meetings. We have publicly shared the datasets with a permissible license.
STT model
We use faster-whisper’s Turbo variant, running at FP16 precision, to transcribe the audio files.
Test data validation
We manually go through the raw Whisper transcripts in parallel with the audio and correct errors, abiding by the established rules.
In our initial attempt, we noticed that letting an LLM model go through the transcript first introduces a lot of biases, and the final results may be skewed towards certain models that match its writing style.
We then compare the human-redacted text with the LLM redacted text and remove any remaining mistakes we saw. We settle on a few rules for edge cases (also included in the model instructions):
- Website names should be written in Latin.
- Product names should be written in Latin (e.g., “Docker”, “Python”, “.NET”).
- Always use the correct article (subject vs non-subject), even if the speaker pronounced it otherwise.
- Verbalization of foreign terms should stay in Cyrillic (e.g., “докеризация”, “пулване”, “пушване”)
- No adding or removing filler words, unless they are crucial for the understanding or correcting significantly malformed sentences.
Potentially, some errors remain, or cases where it is too ambiguous to decide on the correct form and annotator bias was introduced, but we believe that the signal is good enough for us to make a reasonable correlation. We provide the transcribed and redacted data below.
Metrics
One of the more commonly used metrics for judging the quality of ASR is WER (Word Error Rate), or the percentage of words that were not correctly written, based on edit distance, compared to the ground truth.
In the example below, we can see that BgGPT omits a “си”, erroneously replaces the word “мисля” with “смятам” (which is not perfect but at least grammatically correct) and makes an arguable mistake of the word “перформънс” (performance). So in this case, the edit distance in terms of words is equal to 3. Given that the total number of words in this cue is 14, WER = 3/14 = 0.214. While the mistakes for Gemini are different, it also receives the same WER.

We showcase WER and subsequently, WER Reduction % (or what percent of the errors did we manage to remove). Normalized WER refers to the normalization of the words before the calculation - lower case, removed punctuation, etc.
As we can see, BgGPT consistently outperformed all open-weight models, even significantly larger and reasoning-capable ones like DeepSeek v3.2. While the SOTA closed models that perform reasoning may be competitive or slightly better, the gap is relatively small and with adjustments to the prompt techniques and domain-relevant lexicons, we believe it can be closed even further. Nevertheless, on observation of the corrections, Gemini is very robust to different prompts and, due to its strong reasoning capabilities, is able to detect some subtle errors, as mentioned above, that BgGPT 27B may struggle with. Meanwhile, BgGPT can catch some grammatical and spelling errors that the other models don’t, simply because it is better adapted to the Bulgarian language. The greatest example of this is words like “оттук”, “навреме”, etc., which both Whisper and the other models leave incorrectly separated.
NOTE: The BgGPT model used in the experiments is the quantized FP8 version, which is not worse than its original BF16 version but is significantly faster and cheaper.
Processing one hour of transcripts with BgGPT costs roughly $0.03, similarly to Gemma-3. The same hour costs $0.33 with Gemini 3 Flash, $1.36 with GPT-5.2, and $1.79 with Claude Sonnet 4.5. When you're running these AI flows at scale, that difference adds up fast. For example, if we choose Gemini 3 Flash as our model of choice, we can expect an API bill of 330$ for 1000h of transcripts, compared to 33$ for BgGPT.
This is why when we consider price/performance, BgGPT is the clear winner.
The qualitative impact was just as important. Before LLM refinement, our transcripts were "mostly right, but annoying to read." Afterwards, they were reliable enough to use directly, without cross-referencing with the audio track. This might sound like a small thing, but it's the difference between transcripts being a byproduct and transcripts being a product.
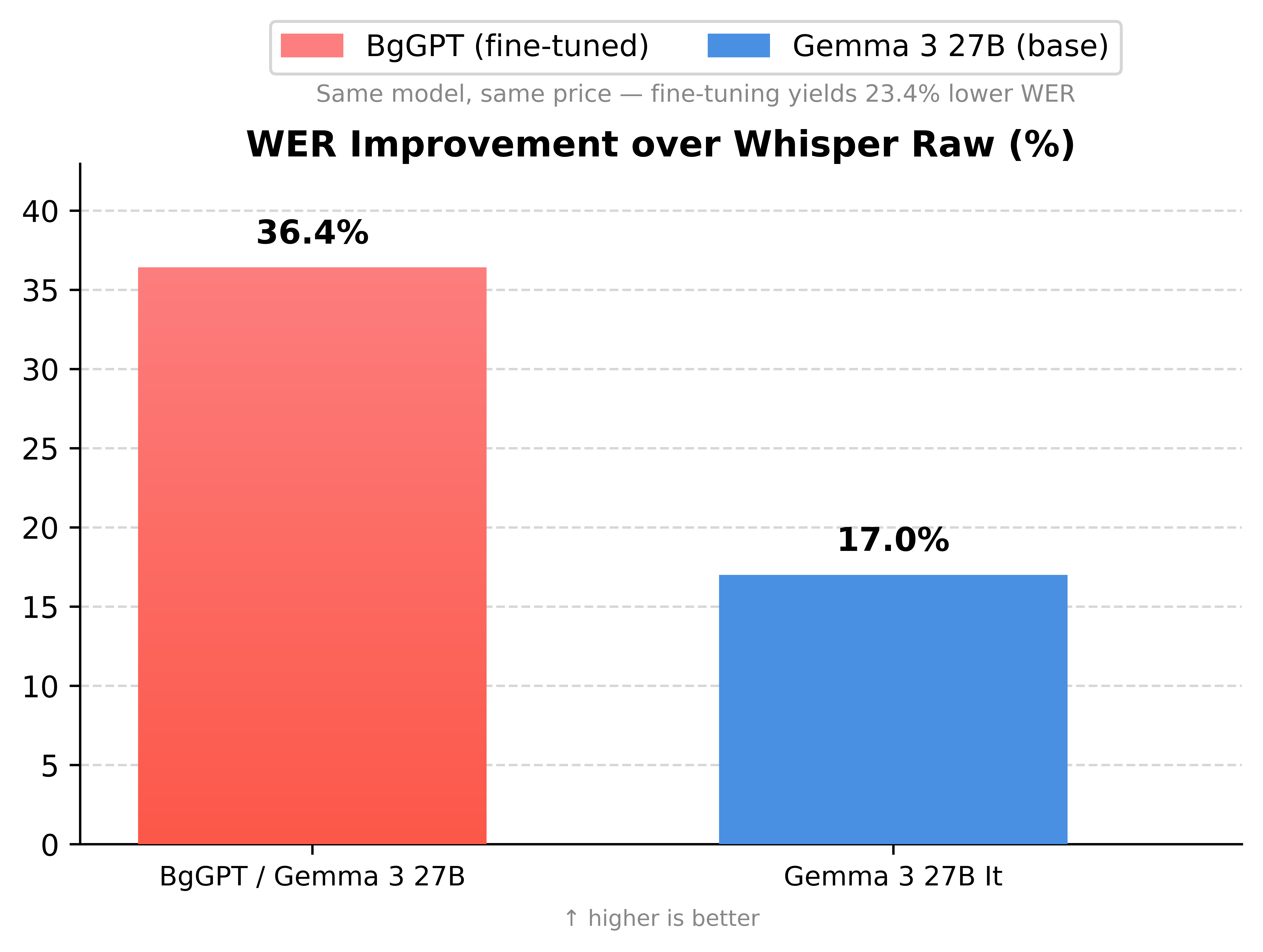
BgGPT's Bulgarian fine-tuning more than doubled the WER improvement compared to base Gemma 3 27B - 36.4% vs 17.0% — at essentially the same (or even lower in the case of FP8) inference cost. All of this combined made BgGPT the sensible model of choice for our use case.
[1] Radford et al., Robust Speech Recognition via Large-Scale Weak Supervision, 2022. [2] Yang et al., Generative Speech Recognition Error Correction with Large Language Models, 2023. [3] ASR Error Correction using Large Language Models, 2024. [4] Courtland et al., Punctuation Restoration using Transformer Models, 2020. [5] Burgas TV, "България избира своите кметове и гласува на референдум," YouTube, Oct. 25, 2015. [Online]. Available: https://www.youtube.com/watch?v=MwL_M3oua4k [6] Подкаст Срещи, "еп. 4 Краси Панчев: Мисиите, които те променят," YouTube, Nov. 12, 2025. [Online]. Available: https://www.youtube.com/watch?v=f-pS0C3AYa0 [7] Народно събрание на Република България, "Пленарно заседание на 51-о Народно събрание," parliament.bg, Jan. 22, 2026. [Online]. Available: https://parliament.bg/bg/video/ID/1946 [8] Народно събрание на Република България, "Комисия за прякото участие на гражданите, жалбите и взаимодействието с гражданското общество – част 2," parliament.bg, Jan. 22, 2026. [Online]. Available: https://parliament.bg/bg/video/cID/1769